Jeux de données
Datasets librement téléchargeables pour l'IA (entraînement et évaluation de modèles)
MNIST (Handwritten Digits)�
MNIST est le dataset le plus connu pour débuter en vision par ordinateur et réseaux de neurones.
70 000 images en niveaux de gris 28×28 pixels représentant des chiffres manuscrits (0 à 9), divisées en 60 000 images d’entraînement et 10 000 de test. Idéal pour tester la classification d’images.

Téléchargement (4 fichiers au format idx/gzip :
- Images d’entraînement : http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
- Étiquettes d’entraînement : http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
- Images de test : http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
- Étiquettes de test : http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
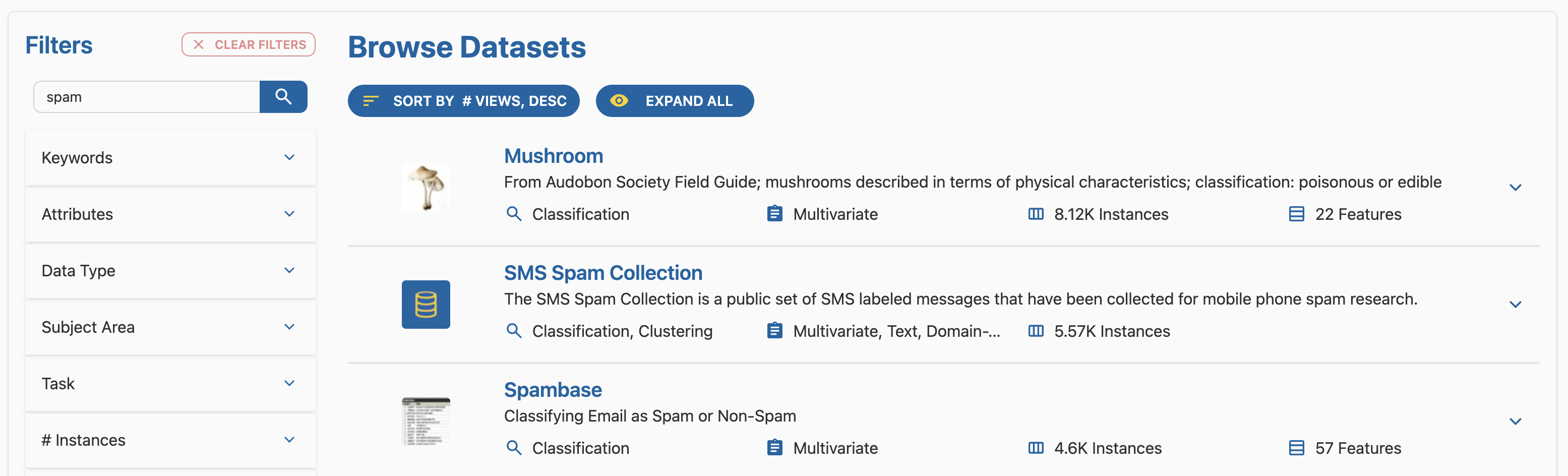
UCI Machine Learning Repository
UCI Machine Learning Repository est un site de référence qui propose des jeux de données (datasets) pour l’apprentissage automatique et la recherche en data science.
Dans son catalogue, on peut trouver des datasets pour classifier des e-mails en “spam” ou “non-spam” à partir de variables qui décrivent le contenu des messages (fréquence de certains mots, de caractères, longueur de séquences de majuscules, etc.).
Téléchargement :
- Page principale du catalogue : https://archive.ics.uci.edu/
- Exemple Spambase (spam/non-spam) : https://archive.ics.uci.edu/dataset/94/spambase
→ Téléchargement direct du fichier de données : https://archive.ics.uci.edu/static/public/94/data.csv
CIFAR-10 / CIFAR-100
CIFAR-10 est un classique pour la classification d’images en couleur.
60 000 images 32×32 pixels en couleur réparties en 10 classes (avion, automobile, oiseau, chat, cerf, chien, grenouille, cheval, bateau, camion) pour CIFAR-10. CIFAR-100 monte à 100 classes. Très utilisé pour comparer les architectures de réseaux convolutifs.

Téléchargement :
- CIFAR-10 : https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
- CIFAR-100 (version plus difficile) : https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz
ImageNet
ImageNet est la référence historique pour la vision par ordinateur moderne.
Plus de 14 millions d’images annotées sur ~21 000 classes (version complète) ou ~1 000 classes pour le challenge ILSVRC (souvent appelé simplement ImageNet). C’est sur ce dataset que sont nés AlexNet, VGG, ResNet, etc.

https://www.image-net.org/ - https://www.image-net.org/update-mar-11-2021.php
Téléchargement :
- Images ILSVRC 2012 (train + val) : https://image-net.org/download-images
- Les liens exacts apparaissent après connexion sur https://www.image-net.org/download.php
- Versions plus légères et prêtes à l’emploi (ILSVRC 2012 subset ou versions prétraitées) : https://huggingface.co/datasets/imagenet-1k
Le téléchargement nécessite une inscription gratuite.
La version complète est très volumineuse (plusieurs centaines de Go). On utilise donc souvent des sous-ensembles ou des versions prétraitées sur Hugging Face ou Kaggle.
Common Objects in Context (COCO)
MS COCO est le standard pour la détection d’objets, la segmentation et le captioning d’images.
Environ 330 000 images avec plus de 1,5 million d’objets annotés (bounding boxes, masques de segmentation, légendes en langage naturel).
MS COCO est très utilisé pour entraîner des modèles comme YOLO, Mask R-CNN, BLIP, etc.

Téléchargement :
- 2017 Train images : http://images.cocodataset.org/zips/train2017.zip
- 2017 Val images : http://images.cocodataset.org/zips/val2017.zip
- 2017 Test images : http://images.cocodataset.org/zips/test2017.zip
- Annotations (train/val) : http://images.cocodataset.org/annotations/annotations_trainval2017.zip
Open Images Dataset (Google)
Open Images est une très grande base de données ouverte proposée par Google.
Plus de 9 millions d’images annotées avec ~600 classes, bounding boxes, masques de segmentation et relations visuelles. Une excellente alternative moderne et massive à ImageNet.

Téléchargement :
- Images + annotations (plusieurs variantes) : https://storage.googleapis.com/openimages/web/download.html
Hugging Face Datasets
Hugging Face Datasets est la plateforme communautaire la plus utilisée en 2026 pour charger des datasets en une ligne de code.
Des milliers de datasets prêts à l’emploi (texte, images, audio, multimodal) : GLUE/SuperGLUE (NLP), Common Voice (parole), LAION-Aesthetics (images esthétiques), etc.
C’est devenu l’endroit central pour les chercheurs et développeurs IA grâce à son intégration avec les modèles Transformers.
Téléchargement :
- MNIST : https://huggingface.co/datasets/mnist
- Fashion-MNIST : https://huggingface.co/datasets/zalando/fashion-mnist
- IMDb Reviews : https://huggingface.co/datasets/imdb
- COCO (captions) : https://huggingface.co/datasets/HuggingFaceM4/COCO
- ImageNet-1k : https://huggingface.co/datasets/imagenet-1k
Kaggle
Pourquoi utiliser Kaggle pour ces datasets ?
- Téléchargement simple et rapide via une interface conviviale.
- Accès à des notebooks et exemples de code pour démarrer rapidement.
- Communauté active pour partager conseils et solutions.
Ces datasets sont parfaits pour entraîner des modèles d’intelligence artificielle dans le domaine de la vision par ordinateur, avec des images variées et annotées.
Téléchargement :
-
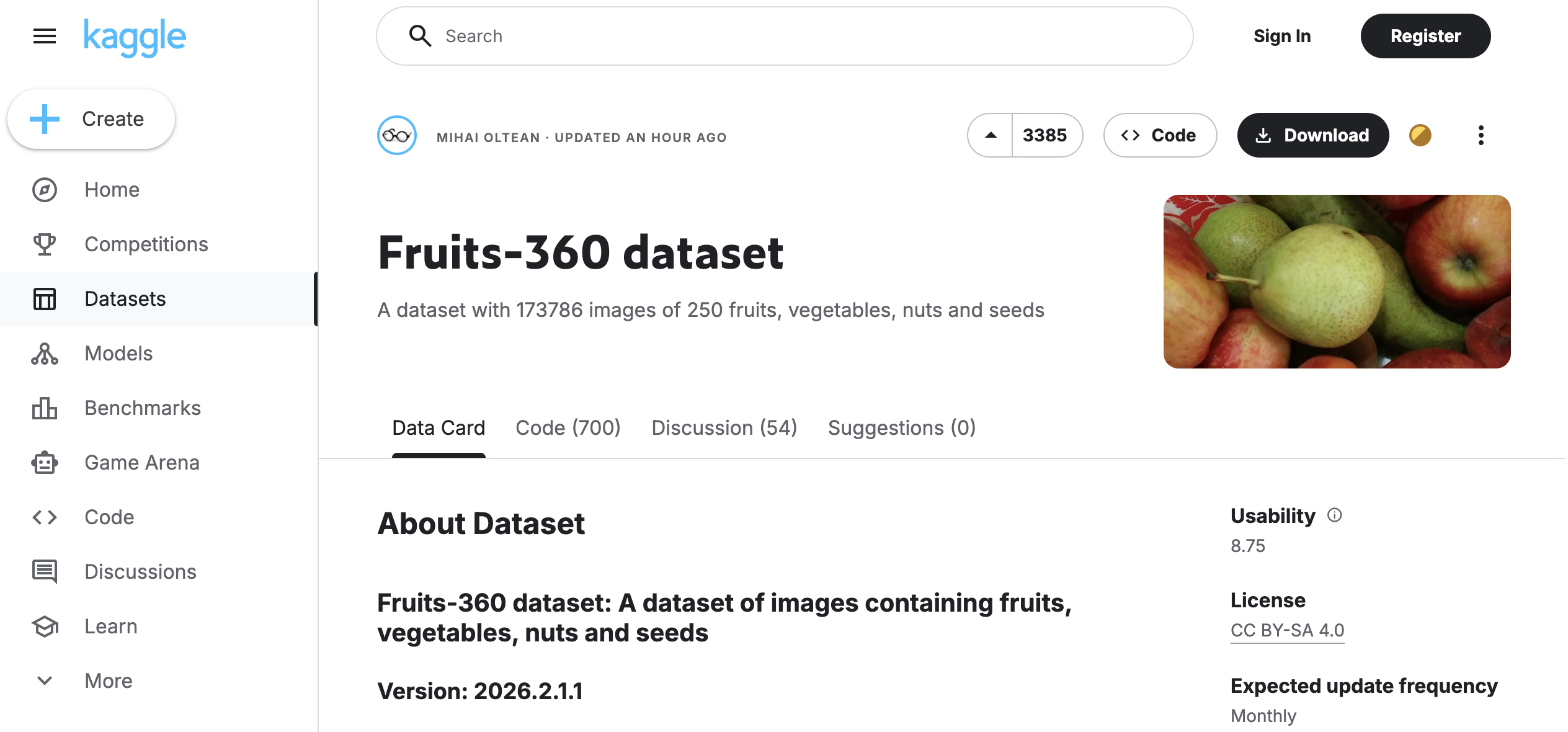
Fruit Images Dataset
Ce dataset contient des milliers d’images de fruits variés, parfait pour des projets de classification ou de reconnaissance d’images. Les fruits sont photographiés sous différents angles et conditions d’éclairage, ce qui permet d’entraîner des modèles robustes.- Exemples de fruits : pommes, bananes, oranges, fraises, raisins, etc.
- Utilisation : classification, détection d’objets, segmentation.
Lien de téléchargement :
https://www.kaggle.com/datasets/moltean/fruits -
Animal Images Dataset
Ce dataset propose une grande variété d’images d’animaux dans leur habitat naturel ou en studio, couvrant plusieurs espèces. Idéal pour des tâches de classification multi-classes ou d’identification d’espèces.- Exemples d’animaux : chiens, chats, oiseaux, chevaux, lions, éléphants, etc.
- Utilisation : reconnaissance d’espèces, classification, apprentissage profond.
Lien de téléchargement :
https://www.kaggle.com/datasets/alessiocorrado99/animals10
Autres jeux de données populaires
- Fashion-MNIST : version “plus dure” de MNIST avec 10 catégories de vêtements (remplace souvent MNIST pour benchmarker)
https://github.com/zalandoresearch/fashion-mnist Téléchargement dans le README ou via Hugging Face : https://huggingface.co/datasets/zalando/fashion-mnist
- IMDb Reviews : 50 000 critiques de films pour la classification de sentiment (positif/négatif)
https://huggingface.co/datasets/imdb Téléchargement : https://huggingface.co/datasets/imdb (ou version brute : http://ai.stanford.edu/~amaas/data/sentiment/)
- SQuAD : questions-réponses sur Wikipédia (très utilisé en NLP extractif)
Téléchargement :