2) Keras et TensorFlow
Nous allons exploiter le modèle d'IA au format Keras dans un programme TensorFlow (Python).
Utiliser un modèle d'IA avec TensorFlow
Dans le tutoriel précédent "Teachable Machine", nous avons vu comment entraîner un modèle avec Teachable Machine et exporter le modèle au format Keras.
Voici maintenant les principales étapes nécessaires pour utiliser ce modèle dans un programme TensorFlow (Python).
Importation des bibliothèques
Pour utiliser un modèle Keras dans un programme Python avec TensorFlow, nous devons importer les bibliothèques nécessaires.
from tensorflow.keras.models import load_model
from PIL import Image, ImageOps
import numpy as np
Explication des bibliothèques importées :
load_model: pour charger le modèle KerasPIL(Pillow) : pour ouvrir et manipuler les imagesnumpy: pour manipuler les tableaux de données numériques
Chargement du modèle – load_model
Voici le code Python qui charge le modèle Keras exporté depuis Teachable Machine, dans la variable model :
from tensorflow.keras.models import load_model
model = load_model('keras_model.h5', compile=False)
compile=Falseest obligatoire avec les modèles exportés par Teachable Machine
Ouverture d'une image
Voyons comment ouvrir une image, la redimensionner et la préparer pour le modèle, en utilisant la bibliothèque Pillow (PIL).
Voici le code Python qui importe les bibliothèques nécessaires :
from PIL import Image, ImageOps
Méthodes les plus utilisées :
Image.open(chemin)→ ouvre une image.convert("RGB")→ force le mode RGB (3 canaux)ImageOps.fit(image, size, method)→ redimensionne + rogne pour obtenir exactement 224x224 tout en gardant le ratio
Méthodes de resampling recommandées :
| Méthode | Qualité | Vitesse | Usage recommandé |
|---|---|---|---|
Image.Resampling.NEAREST | basse | très rapide | aperçu rapide |
Image.Resampling.BILINEAR | moyenne | rapide | usage général |
Image.Resampling.BICUBIC | bonne | moyen | photos classiques |
Image.Resampling.LANCZOS | très bonne | lent | recommandé pour Teachable Machine |
Conversion d'une image
Pour faire une prédiction, le modèle attend une image sous forme de tableau numpy.
Il nous faut donc convertir l’image en un tableau numpy.
Voici le code Python qui convertit le contenu de la variable image en un tableau numpy, dans la variable image_array :
import numpy as np
image_array = np.asarray(image)
→ transforme l’image PIL en tableau numpy de forme (hauteur, largeur, 3) avec des valeurs 0–255
Notre variable image_array contient un tableau 3D de forme (224, 224, 3) c'est à dire un vecteur représentant une image :
- 224 pixels de hauteur
- 224 pixels de largeur
- 3 canaux de couleur (RGB) qui contiennent un entier entre 0 et 255 pour chaque pixel
Normalisation des pixels
Pour obtenir une prédiction, il faut normaliser les valeurs des pixels (0–255) dans l’intervalle [-1 ; +1].
Normaliser signifie mettre à l’échelle les valeurs pour qu’elles soient comprises dans une plage spécifique.
Voici le code Python qui normalise le tableau image_array et le stocke dans la variable image_array_normalized :
image_array_normalized = (image_array.astype(np.float32) / 127.5) - 1.0
Notre variable image_array_normalized contient un tableau 3D de forme (224, 224, 3) c'est à dire un vecteur représentant une image :
- 224 pixels de hauteur
- 224 pixels de largeur
- 3 canaux de couleur (RGB) qui contiennent (maintenant que nous avons normalisé) un nombre flottant entre -1 et +1 pour chaque pixel
Ajout du nombre d’images
Notre variable image_array_normalized contient un tableau 3D de forme (224, 224, 3),
mais, pour faire une prédiction, le modèle a besoin de connaître le nombre d’images en entrée (appelé « batch size »).
La méthode model.predict() attend un paramètre sous la forme (nombre_d’images, 224, 224, 3).
Et notre variable image_array_normalized ne contient qu’une seule image.
Voici le code Python qui ajoute cette dimension supplémentaire :
batch = np.expand_dims(image_array_normalized, axis=0)
Explication :
np.expand_dimsajoute une nouvelle dimension au tableauaxis=0signifie que la nouvelle dimension sera ajoutée au début (avant les dimensions existantes)- Résultat :
batcha maintenant la forme(1, 224, 224, 3)(1 image de 224x224 pixels avec 3 canaux)
Si on avait 5 images à prédire en même temps, la forme serait (5, 224, 224, 3).
Prédiction – model.predict
Voici le code Python qui donne au modèle, le lot d'images préparées (dans la variable batch), pour obtenir une prédiction.
prediction = model.predict(batch, verbose=0)
Explication :
model.predict(batch)→ fait une prédiction sur les données d’entréebatchverbose=0→ désactive les messages de progression pendant la prédiction- Résultat :
predictionest un tableau numpy contenant les probabilités pour chaque classe- Exemple :
prediction=[[0.942, 0.031, 0.027]]pour 3 classes (Pierre, Feuille, Ciseaux)
Lecture des labels
Voici le code Python qui lit le fichier labels.txt et lit chaque ligne pour créer une liste appelée class_names :
with open("labels.txt", "r", encoding="utf-8") as f:
class_names = [line.strip() for line in f.readlines() if line.strip()]
Explication :
open("labels.txt", "r", encoding="utf-8")→ ouvre le fichier en mode lecture avec encodage UTF-8f.readlines()→ lit toutes les lignes du fichierline.strip()→ enlève les espaces et sauts de ligne inutiles- La liste
class_namescontient les noms des classes dans l’ordre (indice 0, 1, 2, ...) - Exemple :
class_names=["Pierre", "Feuille", "Ciseaux"]
Interprétation du résultat
Voici le code Python qui interprète la prédiction pour obtenir la classe la plus probable et sa confiance associ�ée :
index = np.argmax(prediction[0])
confidence = prediction[0][index]
label = class_names[index]
Explication :
prediction[0]→ accède aux probabilités de la première (et unique) imagenp.argmax(prediction[0])→ trouve l’indice de la classe avec la probabilité la plus élevéeconfidence = prediction[0][index]→ récupère la probabilité associée à cette classelabel = class_names[index]→ récupère le nom de la classe correspondante
- Exemple : si
index = 0, alorslabel = "Pierre"etconfidence = 0.942(94.2 %)
Exemple pratique
Il est possible de créer un petit programme Python qui permet de tester le modèle entraîné avec Teachable Machine sur des photos réelles prises par vous-mêmes.
Concrètement, le programme fera les choses suivantes :
-
Demander à l’utilisateur de choisir une photo (fichier .jpg ou .png)
→ les photos auront été prises avec votre smartphone et transférées par mail sur votre ordinateur -
Charger cette image depuis le disque
-
La transformer pour qu’elle soit exactement dans le format attendu par le modèle :
- passer en mode RGB (trois couleurs)
- redimensionner / rogner pour obtenir précisément 224 x 224 pixels
- normaliser les valeurs des pixels dans l’intervalle [-1 ; +1]
-
Donner cette image transformée au modèle pour obtenir une prédiction
-
Récupérer les probabilités renvoyées par le modèle
-
Identifier la classe la plus probable (celle avec la plus haute probabilité)
-
Afficher un résultat clair et lisible, par exemple :
════════════════════════════════════════════════════
Image analysée : pierre_2025.jpg
Geste reconnu : Pierre
Confiance : 94.2 %
Probabilités détaillées :
• Pierre → 94.2%
• Feuille → 3.1%
• Ciseaux → 2.7%
════════════════════════════════════════════════════
Plus la photo est proche des conditions dans lesquelles le modèle a été entraîné (bon éclairage, fond simple, main bien centrée), meilleure sera la prédiction.
Test de mémorisation/compréhension
TP pour réfléchir et résoudre des problèmes
Nous allons créer un programme capable d'analyser une image de votre choix (jeu Pierre-Feuille-Ciseaux) à l'aide du modèle pré-entraîné.
Vous devez disposer des fichiers suivants dans le même répertoire que votre script :
- Le modèle entraîné :
keras_model.h5 - Le fichier des labels :
labels.txt - Des images de test au format
.jpgou.png(photos prises avec votre smartphone et transférées par mail sur votre ordinateur)
Veuillez créer le fichier Python chifoumi.py et compléter les différentes étapes ci-dessous.
0. Préparation de l'environnement
Avant de commencer à coder, nous allons créer un environnement virtuel Python pour isoler les dépendances de ce projet.
-
Créez un environnement virtuel (recommandé) :
Si vous êtes déjà dans un venv :
deactivate # et pas desactivate :)attentionPython 3.10 est compatible avec TensorFlow, mais en 2026 Python 3.14 n'est pas encore compatible avec TensorFlow.
Une version stable de TensorFlow (2.13) supporte officiellement Python 3.10, 3.11 et 3.12.
Pour créer un nouvel environnement virtuel avec Python 3.10 :
python3.10 -m venv venv_tensorflow
source venv_tensorflow/bin/activate # macOS/Linux
venv_tensorflow\Scripts\activate # WindowsastuceSi s'affiche l'erreur
command not foundoupython3.10 is not recognized, cela signifie que Python 3.10 n'est pas installé ou pas dans le PATH système.Comment installer Python 3.10 à côté de Python 3.14
-
Sur Windows :
- Téléchargez et installez Python 3.10 depuis python.org.
-
Sur macOS/Linux, installez Python 3.10 via Homebrew :
brew install python@3.10
-
-
Puis installez les packages nécessaires :
pip install pillow numpy tensorflow==2.13
1. Importation des bibliothèques
Pour commencer, vous devez importer toutes les bibliothèques nécessaires.
Rappelez-vous que nous avons besoin de manipuler le modèle Keras, de traiter des images avec Pillow et de gérer des tableaux avec NumPy.
Écrivez les instructions d'importation requises en haut de votre script.
Une solution
Vous devez être connecté pour voir le contenu.
Si s'affiche l'erreur Impossible de résoudre l’importation « tensorflow.keras.models, il est probable que la bibliothèque TensorFlow n'ait pas été installée dans votre environnement Python.
Pour l'installer, ouvrez un terminal et exécutez la commande suivante :
pip install tensorflow==2.13
2. Chargement du modèle
L'étape suivante consiste à charger le fichier keras_model.h5 en mémoire.
Rappelez-vous que pour les modèles exportés par Teachable Machine, il est nécessaire d'ajouter le paramètre
compile=Falselors du chargement.
Chargez le modèle dans une variable nommée model, avec la fonction load_model, en prenant soin d'ajouter le paramètre nécessaire.
Une solution
Vous devez être connecté pour voir le contenu.

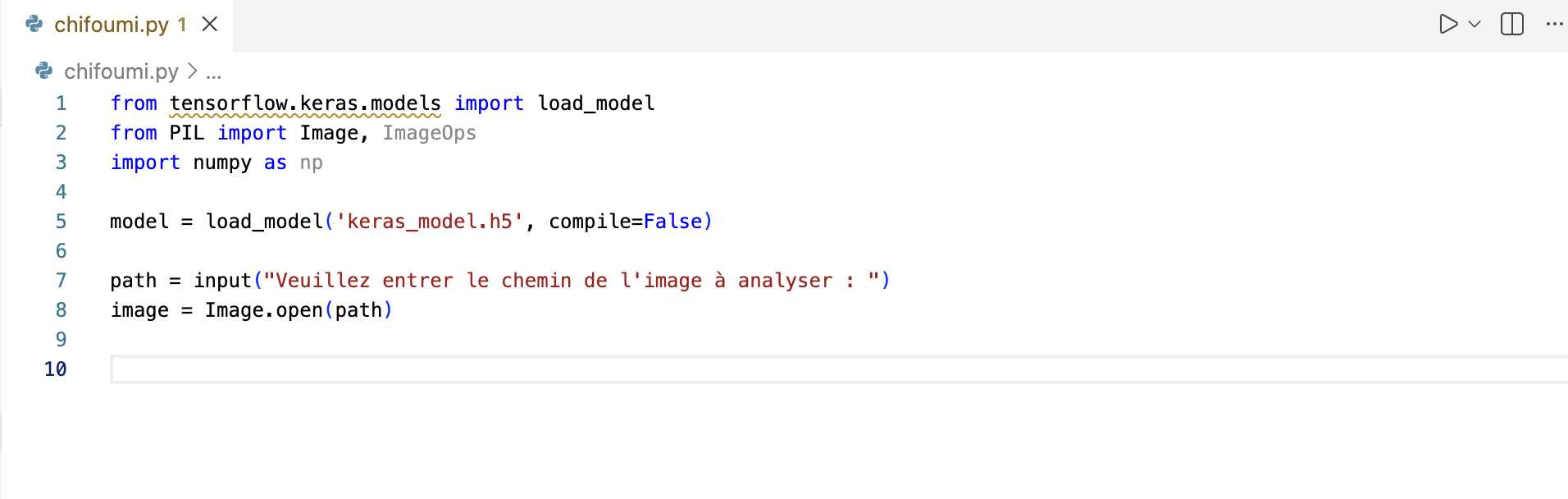
3. Saisie et ouverture de l'image
Le programme doit être interactif.
Vous devez demander à l'utilisateur d'entrer le chemin vers le fichier image que nous souhaitons analyser (par exemple
pierre1.png).
 Redimensionnez votre image
Redimensionnez votre image pierre1.png avec les dimensions 300x300 pixels.
Une fois le chemin récupéré, il faut ouvrir cette image avec Pillow.
Écrivez le code qui demande le chemin à l'utilisateur
"Veuillez entrer le chemin de l'image à analyser", avecinput(), puis stocke l'image ouverte dans une variable nomméeimage.
Une solution
Vous devez être connecté pour voir le contenu.
Pour tester le script, utilisez la commande suivante dans votre terminal, en vous assurant que vous êtes dans le bon répertoire et que l'environnement virtuel est activé :
python chifoumi.py
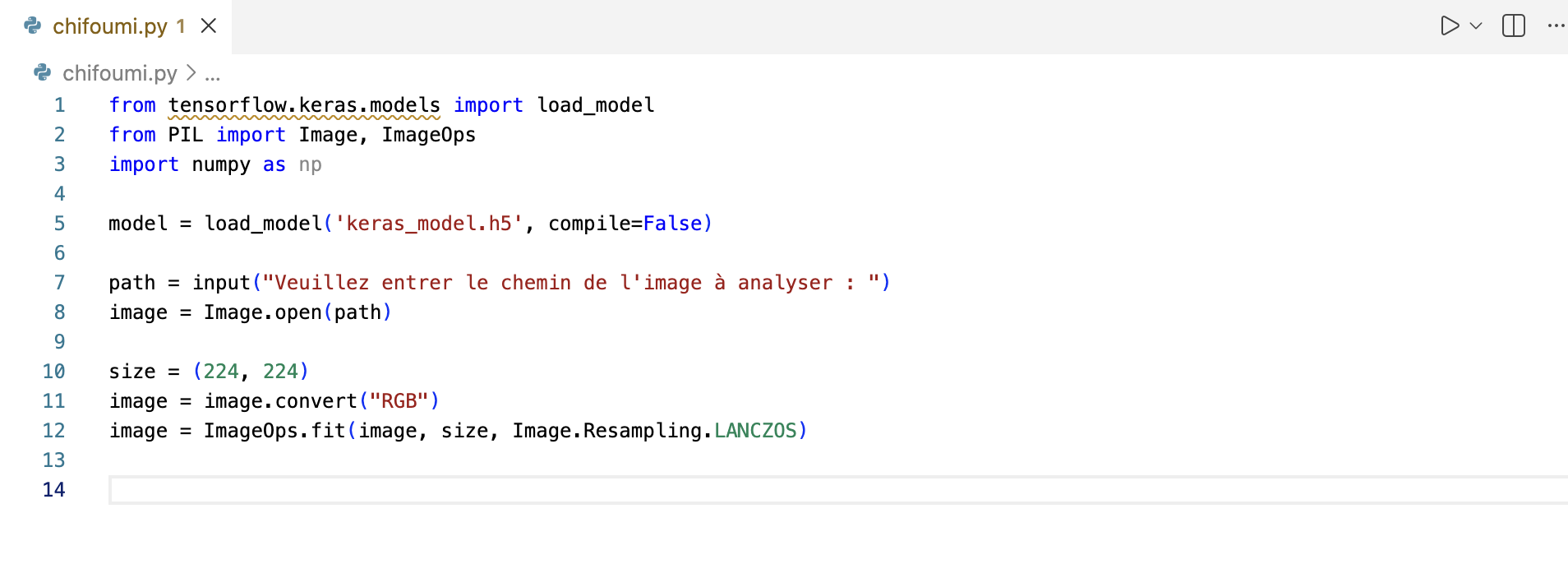
4. Pr�éparation de l'image
Le modèle n'accepte que des images de taille précise (224x224 pixels) et au format RGB.
Vous devez vous assurer que l'image ouverte respecte ces contraintes en la convertissant et en la redimensionnant tout en gardant son ratio.
Effectuez la conversion en RGB, avec convert("RGB"), et redimensionnez l'image à 224x224 en utilisant la méthode de rééchantillonnage recommandée pour la qualité ImageOps.fit(image, size, Image.Resampling.LANCZOS).
Une solution
Vous devez être connecté pour voir le contenu.
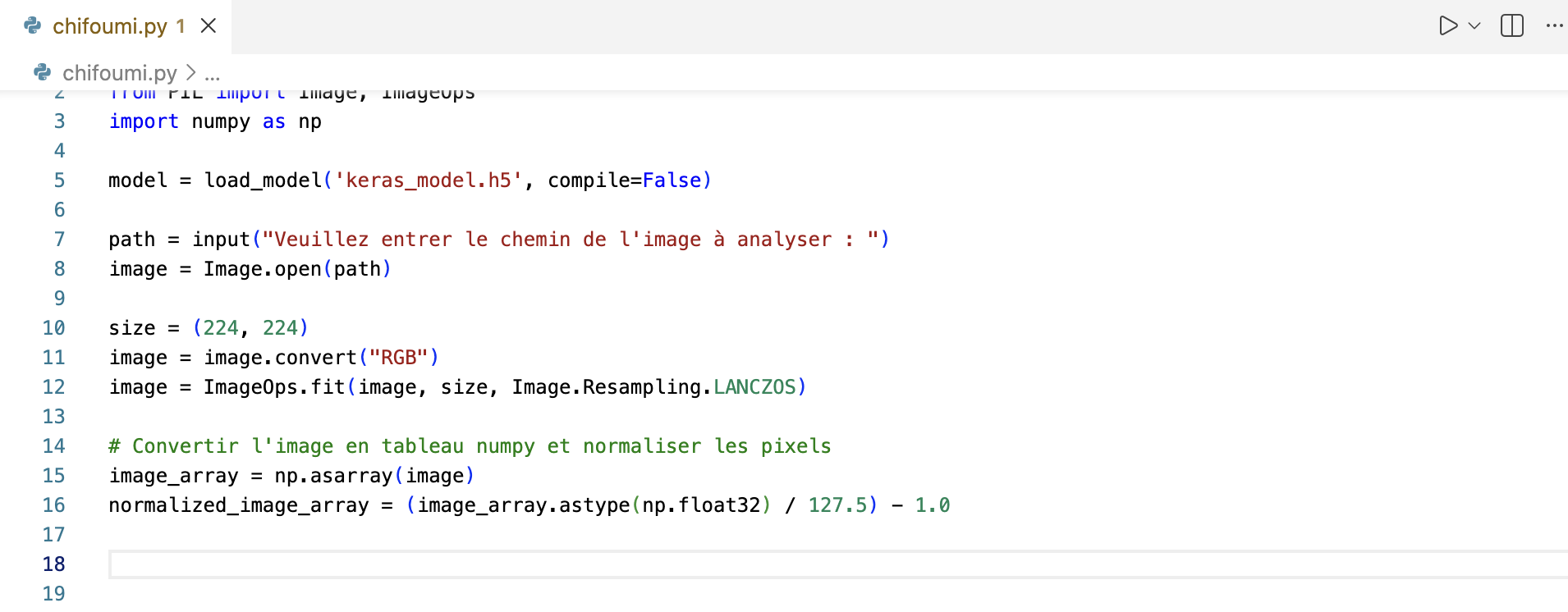
5. Conversion et normalisation
L'image PIL ne peut pas être donnée directement au réseau de neurones. Elle doit être transformée en tableau NumPy, puis ses valeurs de pixels (0-255) doivent être normalisées dans l'intervalle [-1, 1].
Convertissez l'image en tableau, avec
np.asarray(image),puis appliquez la formule mathématique de normalisation :
normalized_pixel = (original_pixel / 127.5) - 1.0
Une solution
Vous devez être connecté pour voir le contenu.
6. Gestion de la dimension de lot
Le modèle attend une entrée de la forme (nombre_d'images, hauteur, largeur, canaux).
Actuellement, votre tableau ne contient qu'une seule image. Vous devez ajouter une dimension supplémentaire, avec
np.expand_dims()et le paramètreaxis=0, pour correspondre au format d'entrée du modèle.
Une solution
Vous devez être connecté pour voir le contenu.
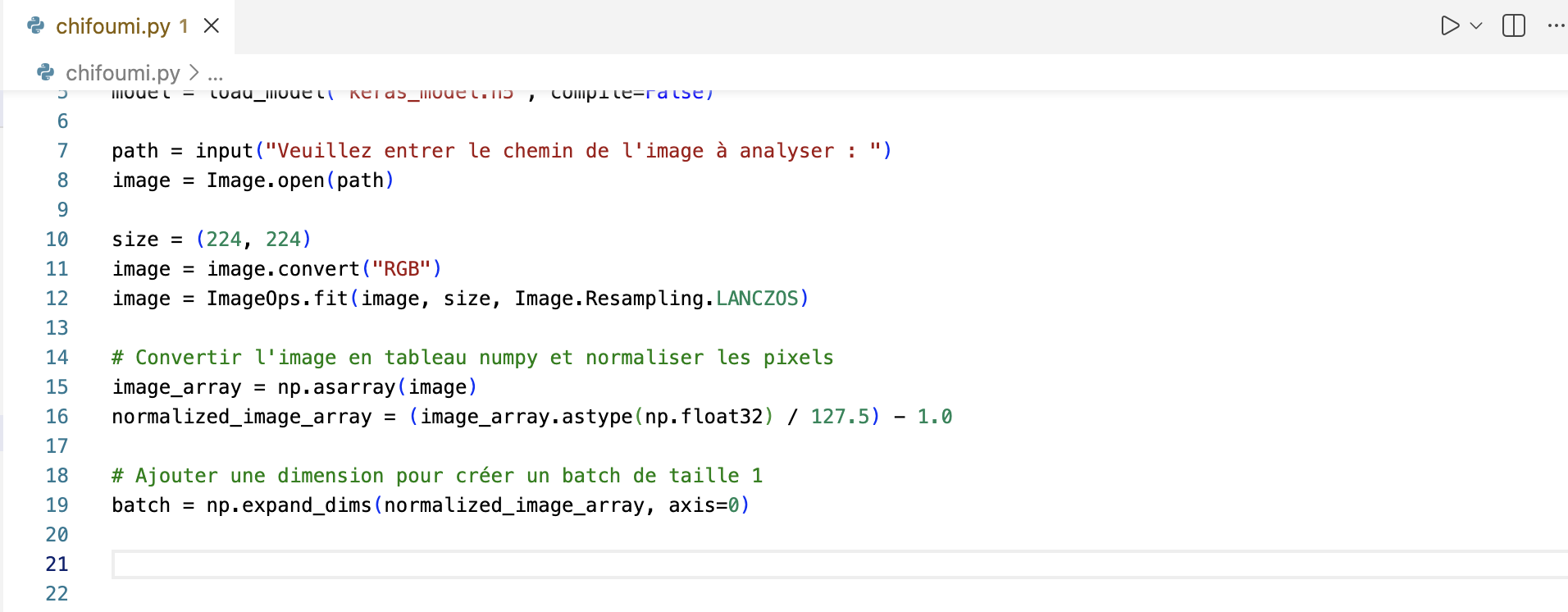
7. Réalisation de la prédiction
Maintenant que les données sont prêtes, vous pouvez les soumettre au modèle.
Récupérez le résultat de la prédiction dans une variable
prediction. Assurez-vous d'exécuter cette opération sans afficher les messages de progression dans la console, avecverbose=0.
Lancez la prédiction sur les données préparées.
Une solution
Vous devez être connecté pour voir le contenu.
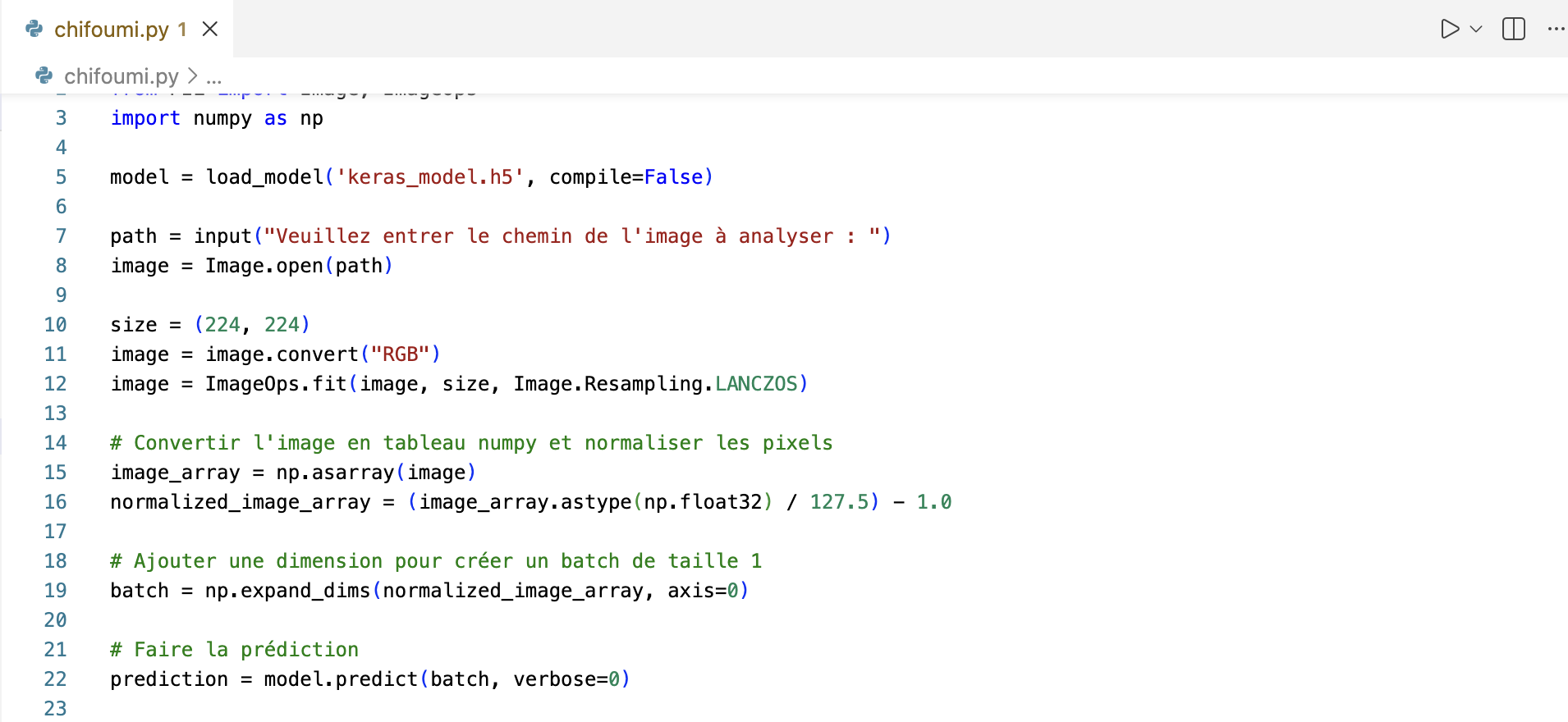
8. Chargement des étiquettes
Pour comprendre la prédiction, il faut associer les indices numériques aux noms des classes (Pierre, Feuille, Ciseaux).
Vous devez lire le fichier
labels.txtet stocker les noms des classes la listeclass_namesen ignorant les lignes vides.
Une solution
Vous devez être connecté pour voir le contenu.
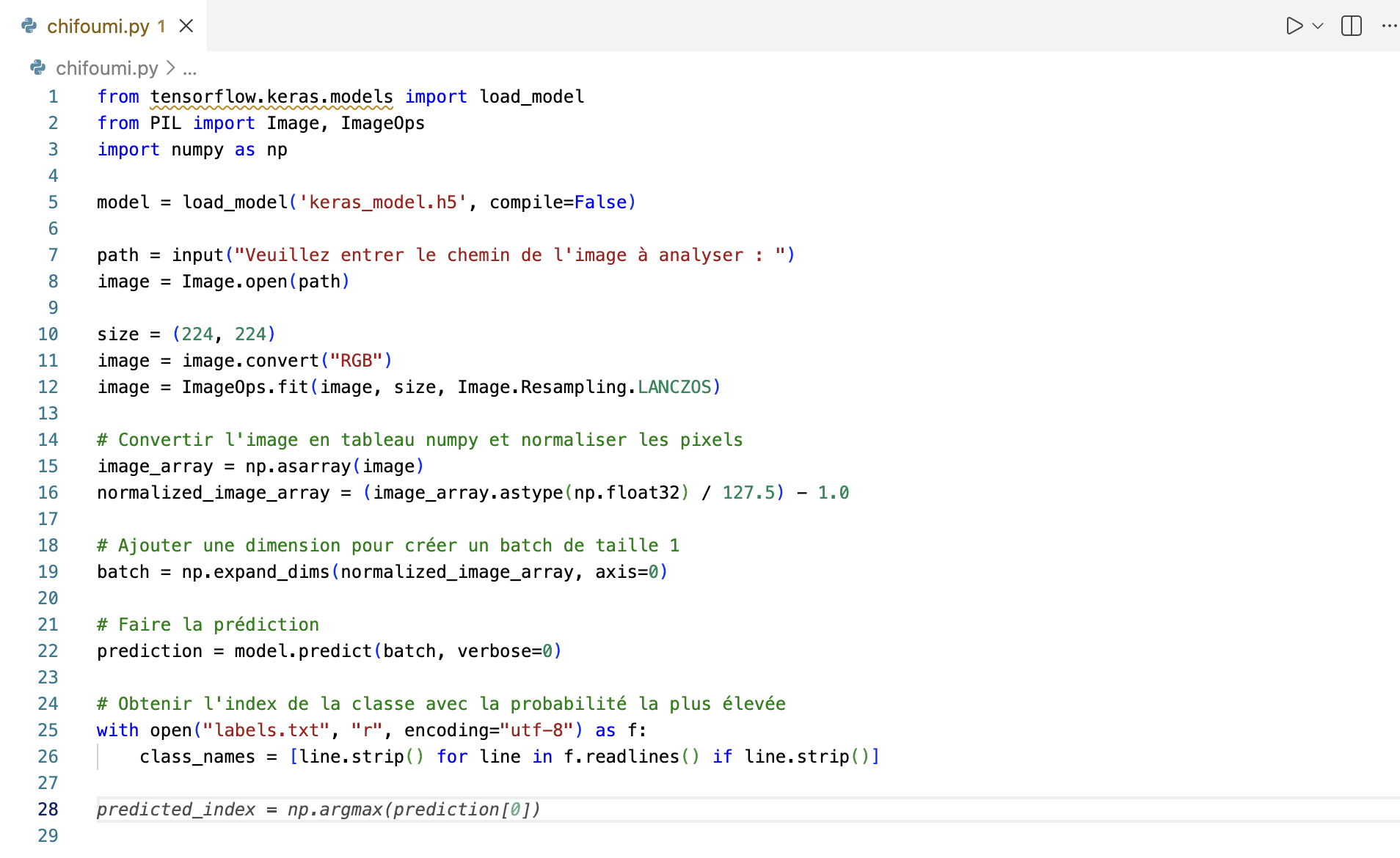
9. Interprétation et affichage
Pour terminer, vous devez extraire la classe la plus probable et son score de confiance.
Ensuite, affichez le résultat sous une forme claire et lisible pour l'utilisateur, en mimant le format de présentation vu dans l'exemple pratique du cours.
Identifiez l'indice de la probabilité maximale, récupérez le label correspondant et affichez le résultat final.
Une solution
Vous devez être connecté pour voir le contenu.
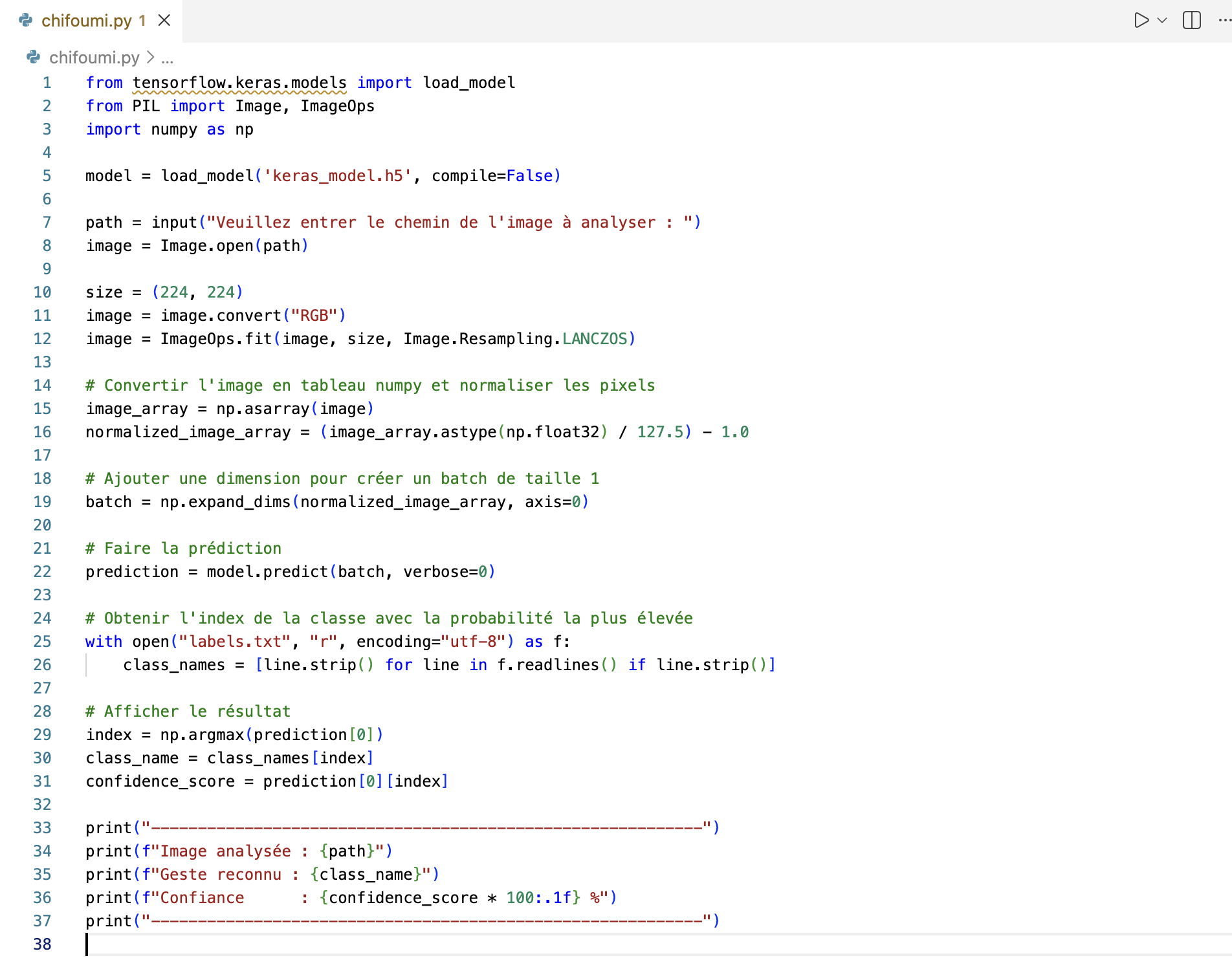
Corrigé
Une solution
Vous devez être connecté pour voir le contenu.
Test du modèle d'IA
Voici un exemple de fichier pierre1.png que vous pouvez utiliser pour tester votre script :
Pour exécuter le script, utilisez la commande suivante :
python chifoumi.py

Dans notre exemple, le modèle a correctement reconnu le geste "Pierre" avec une confiance à 99.9 % !