Détecteur de spam SMS
Comment créer un détecteur de spam SMS avec Scikit-learn ?

- Scikit-learn est particulièrement adapté pour débuter en machine learning grâce à sa simplicité et sa richesse fonctionnelle.
- Scikit-learn est idéal pour des projets de machine learning classiques, mais n’est pas conçu pour le deep learning (réseaux de neurones profonds) où TensorFlow ou PyTorch sont préférés.
Notions théoriques
Qu'est-ce que Scikit-learn ?
Scikit-learn constitue la bibliothèque la plus utilisée en machine learning avec Python.
Scikit-learn vs TensorFlow vs PyTorch
- Scikit-learn est aujourd’hui la bibliothèque de machine learning la plus utilisée en Python.
- TensorFlow est surtout dominant dans le deep learning en production et dans certains projets de Google.
- PyTorch est actuellement le plus utilisé dans le deep learning dans la recherche par la communauté scientifique.
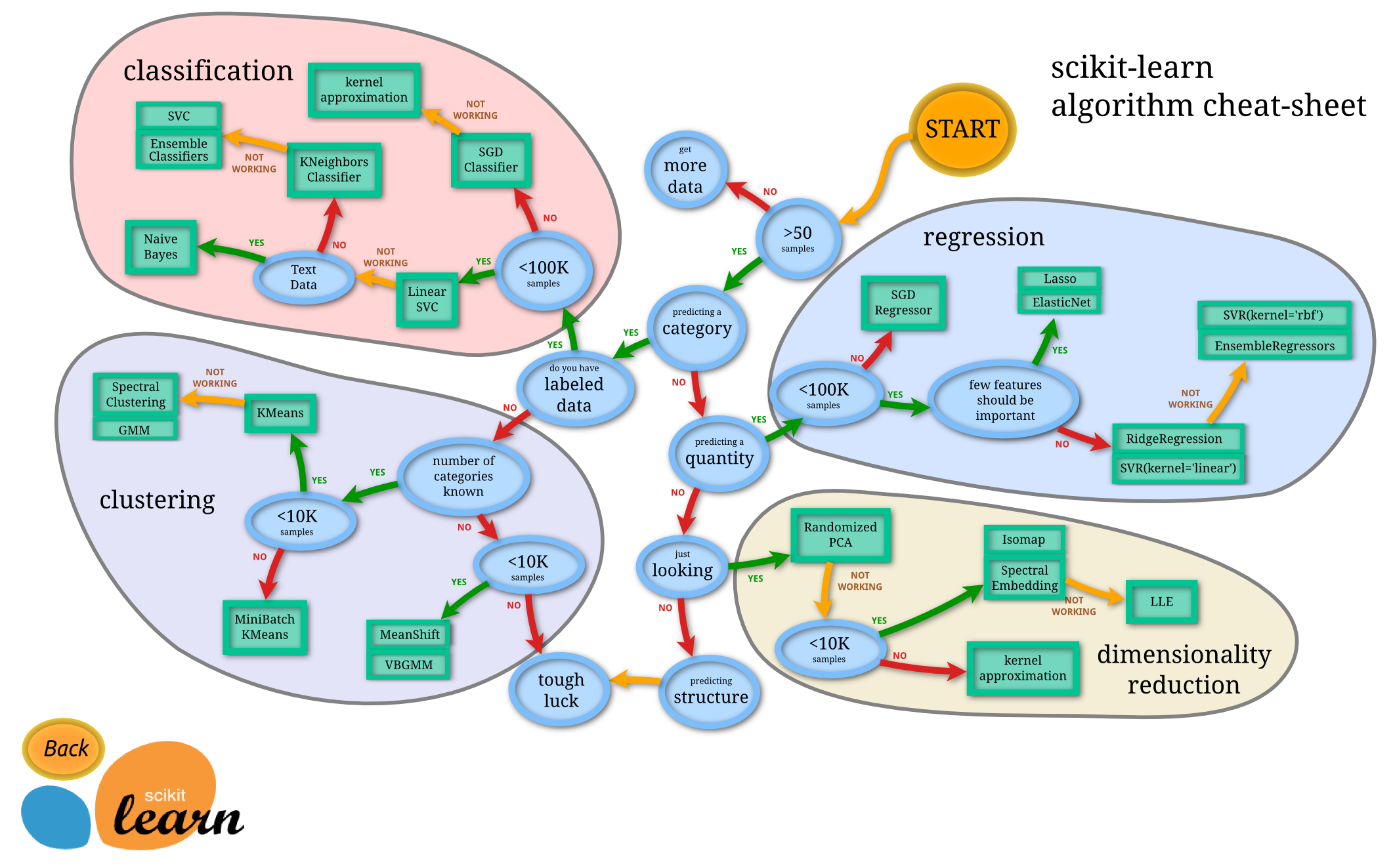 Source : https://fr.wikipedia.org/wiki/Scikit-learn
Source : https://fr.wikipedia.org/wiki/Scikit-learn
Scikit-learn propose de nombreuses bibliothèques d’algorithmes, clé en main, qui contiennent des fonctions pour résoudre de nombreux problèmes classiques :
- classification,
- régression,
- clustering,
- réduction de dimension,
- prétraitement, etc.
Scikit-learn est très utilisés par les data scientists.
Qu'est-ce qu'un data scientists ?
Un data scientist est un expert qui analyse et interprète des données complexes pour en extraire des connaissances, souvent en utilisant des techniques d'intelligence artificielle pour aider dans la prise de décision et automatiser des processus.
Le cœur de la philosophie de Scikit-learn repose sur 3 idées principales :
- Les estimateurs : presque tous les algorithmes suivent la même interface :
- On crée l’objet,
- on appelle
.fit()pour apprendre, - puis
.predict()pour prédire - ou
.score()pour évaluer.
- La cohérence : les étapes (chargement, prétraitement, modèle, évaluation) s’enchaînent de manière très similaire quel que soit l’algorithme choisi.
- L’intégration avec l’écosystème scientifique : numpy, pandas, matplotlib, seaborn sont parfaitement compatibles.
Origine du nom "Scikit-learn"
Scikit-learn vient de :
- SciKit (Scientific kit)
- et learn (machine learning).
Le projet a commencé comme un projet de Google Summer of Code en 2007, et l'idée était de créer une bibliothèque simple et facile à utiliser pour les tâches de machine learning.
Le nom est resté, et maintenant Scikit-learn est l'une des bibliothèques de machine learning les plus populaires pour Python.
3 méthodes d'apprentissage
Voici les 3 grandes familles de méthodes d’apprentissage en Intelligence Artificielle.
Apprentissage supervisé
L’apprentissage supervisé consiste à entraîner un modèle à partir d’exemples étiquetés.
Chaque donnée d’entrée est associée à une réponse correcte, ce qui permet au modèle d’apprendre à prédire cette réponse.
Idée clé
Le modèle apprend en observant des couples entrée → sortie.
Exemples
- Reconnaître des images de chats (image → “chat”)
- Prédire le prix d’une maison (caractéristiques → prix)
Quand l’utiliser
Quand on dispose d’un jeu de données bien annoté et qu’on veut prédire une valeur ou une catégorie.
Apprentissage non supervisé
Ici, aucune étiquette n’est fournie. Le modèle doit découvrir seul la structure cachée des données.
Idée clé
Le modèle cherche des regroupements, des tendances ou des relations internes.
Exemples
- Regrouper des clients selon leurs comportements d’achat
- Réduire la dimension d’un jeu de données pour mieux le visualiser
Quand l’utiliser
Quand on veut explorer ou organiser des données sans savoir à l’avance ce qu’on cherche.
Apprentissage par renforcement
Dans cette approche, un agent apprend en interagissant avec un environnement.
Il reçoit des récompenses ou pénalités selon ses actions et cherche à maximiser la récompense totale.
Idée clé
Apprendre par essais-erreurs, comme un joueur qui s’améliore en jouant.
Exemples
- Un robot qui apprend à marcher
- Une IA qui apprend à jouer aux échecs ou à un jeu vidéo
Quand l’utiliser
Quand un système doit prendre des décisions successives et optimiser un comportement dans le temps.
On également ajouter la famille "Apprentissage auto supervisé" qui est un apprentissage supervisé à partir d'un jeu de données non annoté, souvent en cachant une partie des informations (des mots d'un texte, des morceaux d'images...) afin d'entraîner le modèle à les prédire.
En apprentissage supervisé, le modèle est entraîné sur des données pour lesquelles les réponses sont connues, tandis qu'en apprentissage non supervisé, l'algorithme découvre des structures dans les données par lui-même.
Les principales étapes d’un projet
Voic les principales étapes d’un projet machine learning avec Scikit-learn :
- Charger les données
- Explorer rapidement (shape, describe, head)
- Séparer features (X) et cible (y)
- Diviser en apprentissage / test :
train_test_split - Choisir et instancier un estimateur
- Appeler
.fit(X_train, y_train) - Prédire sur le test :
.predict(X_test) - Évaluer : accuracy_score, confusion_matrix, classification_report, etc.
Les projets Scikit-learn les plus courants
- Classification : prédire une catégorie (spam / pas spam, type de fleur, diagnostic malade / sain…)
- Régression : prédire une valeur numérique continue (prix d’une maison, température demain…)
- Clustering : regrouper des points similaires sans connaître les étiquettes à l’avance
Nous allons nous concentrer ici sur la classification supervisée avec Scikit-learn.
La classification supervisée
Dans la classification supervisée, on dispose d’exemples étiquetés (X, y).
L’objectif consiste à apprendre une fonction f telle que f(X) ≈ y.
Scikit-learn propose de nombreux classifieurs :
- Arbres de décision et forêts aléatoires
- Régression logistique (très utilisée malgré son nom)
- Machines à vecteurs de support (SVC)
- K plus proches voisins (KNeighborsClassifier)
- Réseaux de neurones simples (MLPClassifier)
- Gradient boosting (HistGradientBoostingClassifier, XGBoost via wrapper, etc.)
Notation x ou X et y ou Y en machine learning
En machine learning, on utilise souvent les conventions suivantes :
-
X(majuscule) : matrice des features (données d’entrée), de forme(n_samples, n_features) -
Y(majuscule) : matrice des étiquettes pour plusieurs sorties, de forme(n_samples, n_outputs) -
x(minuscule) : un seul échantillon (une ligne de X), de forme(n_features,) -
y(minuscule) : vecteur des étiquettes (cible), de forme(n_samples,)
Par exemple, pour un dataset avec 100 échantillons et 4 features, on aura :
X: tableau numpy de forme(100, 4)y: tableau numpy de forme(100,)
Cette convention vient de la notation mathématique classique où les variables d’entrée sont souvent notées en majuscule pour les matrices et en minuscule pour les vecteurs.
Le jeu de données
UCI Machine Learning Repository est un site de référence qui propose des jeux de données (datasets) pour l’apprentissage automatique et la recherche en data science.
Dans son catalogue, on peut trouver des datasets pour classifier des e-mails en “spam” ou “non-spam” à partir de variables qui décrivent le contenu des messages (fréquence de certains mots, de caractères, longueur de séquences de majuscules, etc.).
Exemple pratique
Test de mémorisation/compréhension
TP - Détecteur de spam SMS avec Scikit-learn
Objectif
Construire un détecteur de spam SMS simple avec Scikit-learn en Python.
Jeu de données
Téléchargez le fichier de données ici :
https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
Dézippez-le et placez le fichier SMSSpamCollection dans le même dossier que votre script.
Étape 1 – Charger les données et préparer X et y
Écrivez le code suivant pour lire le fichier et transformer les étiquettes en 0 et 1.
import pandas as pd
# Lecture du fichier (séparateur = tabulation)
df = pd.read_csv("SMSSpamCollection", sep="\t", header=None, names=["label", "message"])
# Transformation ham → 0 et spam → 1
X = df["message"]
y = df["label"].map({"ham": 0, "spam": 1})
print("Nombre de messages :", len(X))
print("Répartition :\n", y.value_counts())
Explication du code
Étape 2 – Séparer entraînement et test
Divisez les données (80% entraînement, 20% test) avec un random_state fixe.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print("Entraînement :", len(X_train), "messages")
print("Test :", len(X_test), "messages")
Explication du code
Étape 3 – Créer et entraîner le modèle en une seule passe
Utilisez TfidfVectorizer + MultinomialNB (très courant et efficace pour du texte court comme les SMS).
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
# Pipeline très simple
model = make_pipeline(
TfidfVectorizer(),
MultinomialNB()
)
# Entraînement
model.fit(X_train, y_train)
print("Modèle entraîné !")
Explication du code
Étape 4 – Voir la performance sur les données de test
Calculez seulement l'accuracy et affichez la matrice de confusion.
from sklearn.metrics import accuracy_score, confusion_matrix
# Prédictions
y_pred = model.predict(X_test)
# Résultats
print("Accuracy :", round(accuracy_score(y_test, y_pred), 4))
print("Matrice de confusion :\n", confusion_matrix(y_test, y_pred))
Explication du code
Étape 5 – Tester sur vos propres messages
Demandez à l'utilisateur d'entrer un message et affichez la prédiction.
while True:
message = input("\nEntrez un message (ou 'quitter' pour arrêter) : ")
if message.lower() in ["quitter", "exit", "q"]:
break
prediction = model.predict([message])[0]
proba = model.predict_proba([message])[0]
if prediction == 1:
print("→ SPAM détecté ! (probabilité :", round(proba[1]*100, 1), "%)")
else:
print("→ Message normal (ham) (probabilité spam :", round(proba[1]*100, 1), "%)")
Explication du code
Une solution complète en une vingtaine de lignes de code
Vous devez être connecté pour voir le contenu.